Python Read Data From Multiple Urls and Scrape on Them
Web Scraping, Part 2¶
You take installed BeautifulSoup (bs4) and tried some basic scraping.
If yous accept not yet installed the Requests module, practice it at present (in your virtual environment).
If y'all have not fabricated a virtual environment even so, see these instructions.
The code for this chapter is here.
Using select() instead of notice() or find_all() ¶
In the previous department nosotros covered several normally used commands for scraping with BeautifulSoup:
soup . h1 . text soup . find_all ( "td" , class_ = "city" ) soup . find_all ( "img" ) soup . find ( id = "telephone call" ) In chapter 12 of Automate the Boring Stuff with Python (2d edition), the author covers some other command, the select() method. More info: Read the docs.
This method might concord special entreatment to people used to working with JavaScript, considering the syntax for targeting HTML elements — inside the parentheses of select() — follows the same syntax equally this commonly used JavaScript method:
document . querySelectorAll () So instead of ( "td", class_="city" ) , we would write ( "td.city" ) , and instead of (id="telephone call") , we would write ("#telephone call") .
Note that select() always returns a list, even when but one item is institute.
Exist mindful that the way y'all write out what y'all're looking for depends on whether you lot are calling select() or you are calling find() or find_all() . You'll get errors if you mix up the syntax.
Working with lists of Tag objects¶
Both find_all() and select() always render a Python listing. Each particular in the list is a BeautifulSoup Tag object. You tin can access whatsoever list item using its index — but every bit you would with any normal Python listing.
Attempt this lawmaking in the Python shell:
from bs4 import BeautifulSoup import requests url = "https://weimergeeks.com/examples/scraping/example1.html" page = requests . get ( url ) soup = BeautifulSoup ( page . text , 'html.parser' ) images = soup . select ( 'img' ) print ( images ) You'll run across that you lot have a Python list of IMG elements.
Y'all can phone call .get_text() or .text on a Tag object to get but the text inside the chemical element. To become the text from just i Tag object in a list, use its list index:
cities = soup . select ( 'td.city' ) impress ( cities [ 0 ]) print ( cities [ 0 ] . text ) To get the text from all the items in the list, you demand a for-loop:
for city in cities : impress ( city . text ) If an element has attributes, you can get a Python dictionary containing all of them — again, use an index to see merely 1 detail from the listing:
images = soup . select ( 'img' ) print ( images [ 0 ] . attrs ) Example, running the commands in a higher place in the Python shell:
>>> print ( images [ 0 ] ) <img alt="thumbnail" src="images/thumbnails/park_structures.jpg"/> >>> print ( images [ 0 ] . attrs ) {'src': 'images/thumbnails/park_structures.jpg', 'alt': 'thumbnail'} To get a particular attribute for all the IMG elements, you need a for-loop:
for epitome in images : print ( image . attrs [ 'src' ] ) Again, here's how that would run in the Python trounce:
>>> for image in images : ... print ( image . attrs [ 'src' ] ) ... images/thumbnails/park_structures.jpg images/thumbnails/building.jpg images/thumbnails/mosque.jpg images/thumbnails/turrets.jpg images/thumbnails/russia.jpg >>> View the example web page to become a articulate thought of where those attributes came from:
https://weimergeeks.com/examples/scraping/example1.html
Another way to get a particular attribute from a Tag object is with .become() :
for image in images : print ( image . become ( 'src' ) ) As you lot see, there are diverse ways to do the same thing with BeautifulSoup. If y'all find it confusing, choose 1 way and stick with it.
When in doubtfulness, refer to the BeautifulSoup documentation — it's all on one folio, so search it with Control-F.
Finding inside a Tag object¶
The methods find() , find_all() , and select() work on Tag objects besides as BeautifulSoup objects (types of objects are covered here). Here is an instance:
../python_code_examples/scraping/table_scrape.py¶
1 2 3 iv 5 6 seven 8 ix ten 11 12 13 xiv 15 16 17 18 19 20 21 | from bs4 import BeautifulSoup import requests url = "https://en.wikipedia.org/wiki/List_of_Scottish_monarchs" folio = requests . get ( url ) soup = BeautifulSoup ( folio . text , 'html.parser' ) # become the beginning table in the article table = soup . discover ( 'table' , class_ = 'wikitable' ) # get a list of all rows in that table rows = table . find_all ( 'tr' ) # loop over all rows, become all cells for row in rows : attempt : cells = row . find_all ( 'td' ) # print contents of the second prison cell in the row impress ( cells [ one ] . text ) except : pass |
Once we've got table out of soup (line 9 higher up), we can proceed to find elements inside the Tag object table . First nosotros get a list of all rows (line 12). Then we can loop over the listing of row objects (starting on line 15) and brand a list of all tabular array cells in each row (line 17). From that listing, we tin extract the contents of one or more cells. In the for-loop, past printing cells[1].text (line 19), we will see a list of all Scottish monarchs in the start table on the page.
It's as if nosotros are taking autonomously a set of nested boxes. We become inside the table to become the rows. We get inside a row to become its cells.
Annotation
Using effort / except in the script above enables us to skip over the header row of the tabular array, where the HTML tags are thursday instead of td .
Since the Scottish monarchs folio has multiple tables, the lawmaking higher up should be modified to get them all:
tables = soup . find_all ( 'table' , class_ = 'wikitable' ) And then nosotros will need to loop through the tables:
for table in tables : rows = tabular array . find_all ( 'tr' ) for row in rows : attempt : cells = row . find_all ( 'td' ) # impress contents of the second jail cell in the row print ( cells [ ane ] . text ) except : pass Our prepare of nested boxes actually begins with the folio. Within the page are several tables. Inside each tabular array, we find rows, and within each row, we detect cells. Within the second cell in each row, we notice the proper noun of a male monarch.
Note
The revised script will not work perfectly on the Scottish monarchs page because the tables in that folio are non formatted consistently. The first table on the page has the monarch's name in the second column, but the other tables have it in the first column.
Moving from page to page while scraping¶
In chapter 12 of Automate the Boring Stuff with Python (second edition), Sweigart provides a script to scrape the XKCD comics website ("Projection: Downloading All XKCD Comics"). The code in steps 3 and 4, which are part of a longer while-loop, get the URL from an element on the folio that links to the previous comic. In this way, the script starts on the dwelling page of the site, downloads 1 comic, so moves to the previous mean solar day's comic page and downloads the comic there. The script repeats this, moving to the previous page each fourth dimension, until all comics have been downloaded.
Note
This method is often exactly what y'all need to scrape the information that y'all want.
The trick is to determine exactly how to become the URL that leads to the side by side page to exist scraped.
In the instance of the XKCD site, this code works:
prevLink = soup . select ( 'a[rel="prev"]' )[ 0 ] url = 'https://xkcd.com' + prevLink . get ( 'href' ) The code select('a[rel="prev"]') gets all a elements on the folio that contain the attribute rel with the value "prev" — that is, rel="prev" . This code returns a list, then it'due south necessary to use the list alphabetize [0] to become the commencement list item.
The next line extracts the value of the href aspect from that A chemical element and concatenates it with the base URL, https://xkcd.com .
If you audit the HTML on any XKCD page with Developer Tools, you can find this A chemical element.
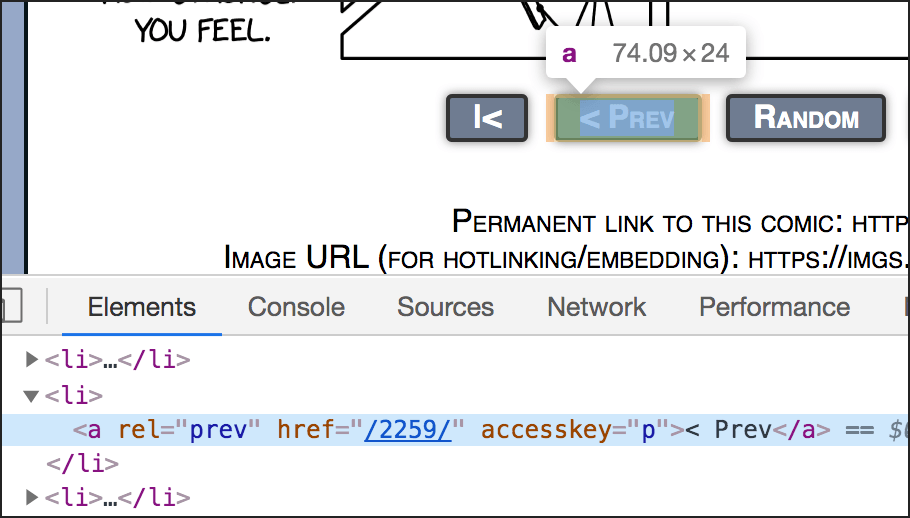
To understand this code better, you lot can run it in the Python beat out. Here I have started on the page at https://xkcd.com/2260/ —
>>> from bs4 import BeautifulSoup >>> import requests >>> url = 'https://xkcd.com/2260/' >>> page = requests . get ( url ) >>> soup = BeautifulSoup ( page . text , 'html.parser' ) Annotation
I am not starting at the habitation page and I am non looping, because I desire to provide a elementary demonstration of what the code is getting for usa.
Then I continued with the code to become only the "Prev" lawmaking from that ane page:
>>> prevLink = soup . select ( 'a[rel="prev"]' )[ 0 ] >>> print ( prevLink ) <a accesskey="p" href="/2259/" rel="prev">< Prev</a> >>> print ( prevLink . go ( 'href' ) ) /2259/ >>> url = 'https://xkcd.com' + prevLink . become ( 'href' ) >>> print ( url ) https://xkcd.com/2259/ >>> In a higher place, I have printed iii things — prevLink , prevLink.get('href') and url — then I can run into exactly what is being extracted and used.
In the complete script in chapter 12, once the script has that final URL, the while-loop restarts. It opens that page — https://xkcd.com/2259/ — and downloads the comic from it.
This practice of printing the value each time is a mode of testing your code every bit you go — to make sure you are getting what you intend to get. If you have an error, so you must change the line and print information technology again, and repeat until that line of code gets what you want.
Of import
You must empathise that every website is different, so probably no other website in the globe has the same HTML every bit the XKCD website. Notwithstanding, many websites do take Previous and Next buttons. It is necessary to audit the HTML and determine how to extract the side by side- or previous-folio URL (or partial URL) from the HTML on the button.
Some websites apply JavaScript to actuate their Previous and Side by side buttons. In those cases, you volition need to use the Selenium module to navigate while scraping. Selenium is covered in the side by side affiliate.
Moving from page to folio while scraping, Role 2¶
I accept posted two example scripts to help y'all with sites where moving from page to page involves something like this:
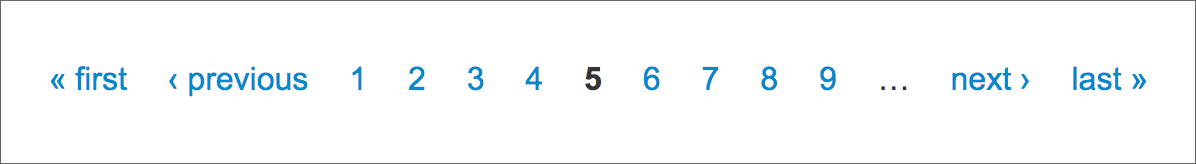
Annotation
Ordinarily yous exercise NOT demand Selenium for these links. They are a lot similar the XKCD case discussed to a higher place.
The two scripts are:
-
mls_pages.py — This one uses the "Get to next page" link until there is no next folio.
-
mls_pages_v2 — This one uses
for i in range(), for utilise if you know how many pages there are.
Annotation that the two scripts do the same thing on 1 particular website, the Players section of the Major League Soccer site. The difference is in the way each script gets the link to the adjacent folio.
Important
Remember that every website is different, then probably no other website in the world has the same HTML as the MLS website. However, many websites use a like set of links to pages.
Harvesting multiple URLs from one page¶
In some cases, you volition desire to get all the URLs from ane page and save them in a file. You would then use some other script to open them 1 past one and scrape multiple pages.
../python_code_examples/scraping/harvest_urls.py¶
1 2 iii 4 v 6 seven 8 9 10 xi 12 thirteen 14 15 16 17 18 nineteen 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | """scrape all the URLs from the article segment of a Wikipedia page and write them into a plain-text file - gets all links - even those that begin with # """ from bs4 import BeautifulSoup import requests # become the contents of i page commencement = 'http://en.wikipedia.org/wiki/Harrison_Ford' folio = requests . get ( start ) soup = BeautifulSoup ( page . text , 'html.parser' ) # name the text file that will exist created or overwritten filename = 'myfile.txt' def capture_urls ( filename , soup ): """harvest the URLs and write them to file""" # create and open the file for writing - notation, with 'westward' this volition # delete all contents of the file if information technology already exists myfile = open up ( filename , 'w' ) # go all contents of simply the article article = soup . find ( id = 'mw-content-text' ) # go all <a> elements links_list = article . find_all ( 'a' ) # get contents of all href='' attributes with a loop for link in links_list : if 'href' in link . attrs : # write one href into the text file - '\n' is newline myfile . write ( link . attrs [ 'href' ] + ' \n ' ) # close and salvage the file subsequently loop ends myfile . close () # call the function capture_urls ( filename , soup ) |
It is likely that yous practise not want header and footer links from the page. You demand to inspect the HTML and ascertain what chemical element holds the main text. For a Wikipedia commodity, in that location's an id attribute with the value 'mw-content-text' , so that'southward what we commencement with in line 24.
When we get all the a elements with links_list = commodity.find_all('a') (line 27), nosotros are getting only the a elements that are inside the DIV chemical element with id='mw-content-text' — because the variable article here is a Tag object containing that entire DIV.
Then nosotros use a loop (lines xxx–33) to look at each item in links_list . We cheque if an href aspect exists in the detail with this line — if 'href' in link.attrs: — and if there is an HREF, then we write the value of that HREF into the file (line 33).
The script to a higher place writes more than than one,400 fractional URLs into a file.
Every bit with the XKCD script in the previous section, here we would also concatenate a base URL with the fractional URL in a scraping script:
base_url = 'https://en.wikipedia.org' url = base_url + '/wiki/Blade_Runner' Information technology should be noted that the harvest_urls.py script collects a lot of partial URLs we would never want, such as internal anchors that link to parts of the same page — #cite_note-1 and #Early_career , for example. To forbid those from beingness written to the file, we could use:
for link in links_list : if 'href' in link . attrs : # eliminate internal ballast links if link . attrs [ 'href' ][: 6 ] == '/wiki/' : # eliminate Wikipedia photograph and template links if link . attrs [ 'href' ][ 6 : xi ] != 'File:' and link . attrs [ 'href' ][ 6 : 14 ] != 'Template' : # write one href into the text file - \northward is newline myfile . write ( link . attrs [ 'href' ] + ' \n ' ) That is a bit clunky, just if you expect up how to slice strings with Python (Control-F search there for "Slice indices"), I think the code will make sense to you.
As a effect, we have nearly 900 fractional URLs instead of more than 1,400.
Of import
You will always need to inspect the HTML of a page to effigy out how all-time to harvest URLs from that item page.
Scrape multiple pages with one script¶
This example shows how you can scrape multiple items from multiple pages, non using a Previous and Next button but (instead) using a nerveless list of partial URLs.
../python_code_examples/scraping/scrape_several_pages.py¶
1 2 3 4 v vi seven 8 9 x 11 12 xiii 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | """scrape a heading and role of a paragraph from multiple pages, using a listing of partial URLs """ from bs4 import BeautifulSoup import requests # links from http://en.wikipedia.org/wiki/Harrison_Ford link_list = [ '/wiki/Melissa_Mathison' , '/wiki/Calista_Flockhart' , '/wiki/Han_Solo' , '/wiki/Star_Wars_Trilogy' , '/wiki/Indiana_Jones' , '/wiki/Air_Force_One_(film)' , '/wiki/Blade_Runner' , '/wiki/Carrie_Fisher' ] # harvest data from each URL def get_info ( page_url ): page = requests . get ( 'https://en.wikipedia.org' + page_url ) soup = BeautifulSoup ( folio . text , 'html.parser' ) try : print ( soup . h1 . get_text ()) # become all paragraphs in the main article paragraphs = soup . find ( id = 'mw-content-text' ) . find_all ( 'p' ) for p in paragraphs : # skip any paragraph that has attributes if not p . attrs : # print 280 characters from the starting time real paragraph on the page print ( p . text [ 0 : 280 ] ) suspension print () # blank line except : impress ( page_url + ' is missing something!' ) # call the office for each URL in the list for link in link_list : get_info ( link ) |
Nosotros are just printing the H1 and the paragraph (rather than saving them to a file or a database) for the sake of simplicity. We are using a listing of only eight partial URLs for the aforementioned reason; normally you would probably have a longer list of pages to scrape.
The key is to write a function that scrapes all the data you want from 1 page (lines 19–35 above). Then telephone call that function inside a for-loop that feeds each URL into the part (lines 38–39).
Moving onward¶
In the next chapter, nosotros'll expect at how to handle more than complex scraping situations with BeautifulSoup, Requests, and Selenium.
.
brashearhessium2000.blogspot.com
Source: https://python-adv-web-apps.readthedocs.io/en/latest/scraping2.html
{kind=link}
Post a Comment for "Python Read Data From Multiple Urls and Scrape on Them"